단발성 에러 매뉴얼이 아닌 실제 운영경험과 DevOps 관점에서 본 장애 극복, 근본 원인 분석‧복구, 그리고 성장의 기록을 남깁니다.

목차
- 1. 예고 없는 장애, 평범한 새벽의 위기
- 2. 로그 분석, 위기의 실체를 드러내다
- 3. 복구 과정: DevOps의 실전
- 4. 진짜 원인과 반복 방지 전략
- 5. 실전에서 배운 교훈과 적용법
- 6. 고급 모니터링 자동화와 성장 스토리
- 7. 실전 Q&A & 운영 팁
- 8. 참고/내부/외부 링크
#1. 예고 없는 장애, 평범한 새벽의 위기
2025년 6월, 일상처럼 시작된 평일 새벽. UptimeRobot, Cloudflare에서 연이어 “504 Gateway Timeout” 알람이 울렸습니다. 사이트는 더 이상 응답하지 않았고, 관리자 페이지조차 접속 불가.
이 시점에 가장 두려웠던 건 서비스 장애 자체가 아니라, 장애의 ‘정확한 위치와 이유’를 즉시 알지 못한다는 점이었습니다.
2025년 6월, 일상처럼 시작된 평일 새벽. UptimeRobot, Cloudflare에서 연이어 “504 Gateway Timeout” 알람이 울렸습니다. 사이트는 더 이상 응답하지 않았고, 관리자 페이지조차 접속 불가.
이 시점에 가장 두려웠던 건 서비스 장애 자체가 아니라, 장애의 ‘정확한 위치와 이유’를 즉시 알지 못한다는 점이었습니다.
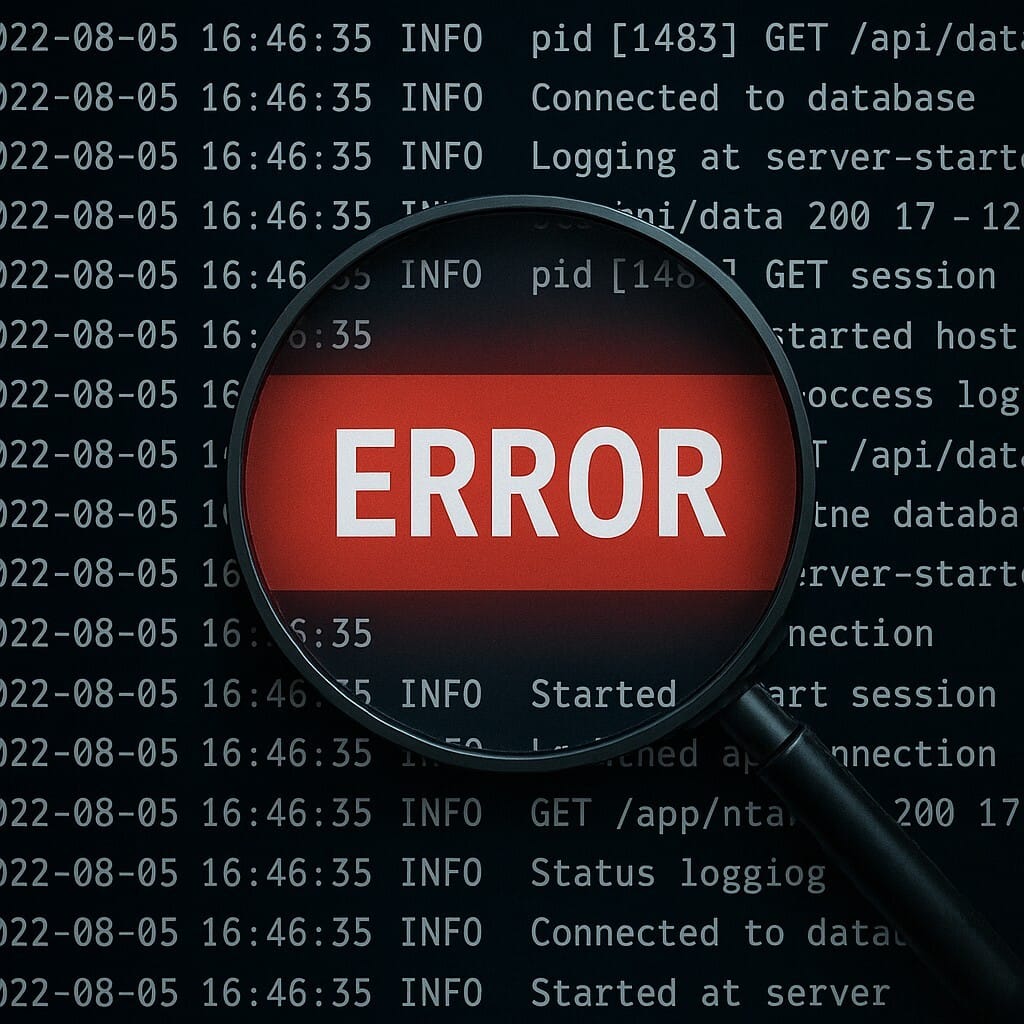
2. 로그 분석, 위기의 실체를 드러내다
- Nginx 로그:[error] 7423#0: *244 upstream timed out…
즉시 PHP-FPM 또는 DB 연동 부하임을 의심. - MariaDB 로그:InnoDB: Error: Table ./wp_options is marked as crashed…
결정적 원인은 DB 테이블 손상이 주요 트리거! - 시스템 로그:디스크 I/O 96% 초과, swap/메모리 임계치 근접, frequent IO wait.
단순 코드 오류가 아니라, 여러 자원 병목·테이블 물리적 손상이 복합적으로 겹친 유형임을 짐작
3. 복구 과정: DevOps의 실전
- Cloudflare 점검 모드로 즉시 전환: 장애 즉시 다운타임 안내 페이지 노출. 사용자 불만 최소화, 신뢰 저하 방지.
- DB 테이블 수동 복구:
mysqlcheck -u root -p --auto-repair --check --optimize mydb
에서 일부 테이블은 dump/export 후 drop/recreate/import까지 수행(실제 손상 복구) - Nginx & PHP-FPM 전체 프로세스 재시작:
systemctl restart nginx php8.1-fpm
이 시점에서 장애 직전, 직후의 각종 지표(로드에버리지, IO, 시스템 로그) 따로 저장해 포스트모템 분석 자료로 활용 - 모니터링 도구 즉각 점검 및 대시보드 실시간 분석: 골든타임 확보.
- 복구 후 실서비스는 즉각 정상화, 하지만 후폭풍(!) 대응 내역 따로 기록
4. 진짜 원인과 반복 방지 전략
- 디스크 I/O 포화 트리거: DB 백업, rsync 등 자가 백업 프로세스가 피크 트래픽 시간과 겹쳐 IO 포화 발생.
- DB 데드락과 InnoDB 손상: 트랜잭션 운영 중 불완전 중단→물리적 테이블 손상으로 이어짐.
- PHP-FPM 세션 풀 설정값 부족: 동시 요청 처리 한계 도달, 응답 대기/타임아웃 난립.
- Node Exporter 알람 무시: 80% 경고 지속, 경고 무시가 반복 다운/손상의 예고 라는 교훈.
재발 방지! – 백업 스케줄: 트래픽 사용량 최소 새벽 시간 + BorgBackup/batch + I/O 쓰로틀링 조합으로 완전 분리, PM/Slack/webhook 통한 경고-즉시 액션 익숙화.
5. 실전에서 배운 교훈과 적용법
- 자동화 백업-실서비스 구간 Time window 완전 분리
- DB Integrity 체크 주 1회 cron 자동화 + 장애 알람
- 트래픽 peak 대비 PHP-FPM, process idle timeout 등 자원 튜닝(1.5~2배)
- 80% 임계치 경고시 즉시 코어 분석→조치 후 로그 이력화
- Cloudflare 우회 페이지 직접 디자인: 단순한 다운 메시지 넘어서 사용자 케어 동시 강조
- 모든 복구 내역·포스트모템 기록(내부 블로그/문서화)
| 문제구간 | 복구 액션 | 자동화 실현 |
|---|---|---|
| DB Table 손상 | dump/export, drop/recreate, import | mysqlcheck, cron스크립트화 |
| 디스크 I/O 한계 | Backup I/O 분리, Borg 제한, 낮은 우선순위 | ionice, cgroup, 백업/서비스 스케줄 분리 |
| Peak 트래픽 PHP-FPM | 설정 max_children 증설, Fail2Ban+재기동 | metric수집, 오토자동 튜닝 |
6. 고급 모니터링 자동화와 성장 스토리
장애 이후 Promtail + Grafana Loki 기반 실시간 로그 수집 도입,
Node Exporter + Grafana 대시보드 실시간 경고 체계 구축,
Alertmanager로 슬랙/메일/앱 알림 전환 → 문제 발생 후 수분 내 즉시 액션 가능.
Node Exporter + Grafana 대시보드 실시간 경고 체계 구축,
Alertmanager로 슬랙/메일/앱 알림 전환 → 문제 발생 후 수분 내 즉시 액션 가능.
운영 위기에서 자동화 도입이 가지는 실질적 변화는 ‘불필요한 반복과 두려움에서의 해방’이었습니다.
매월 장애 시뮬레이션, 서비스/DB 무결성 점검 자동화, 내부 위키에 기록하는 복구 일지를 통해 조직적으로 성장할 수 있었습니다.
7. 실전 Q&A & 운영 팁
Q. 서버 리소스 임계치는 어떻게 정하나요?
A. 서버 구조 · 애플리케이션 peak 기반으로 70~75% 상시, 80~85%는 경보설정, SSD, HDD 차이·백업구간 고려.
A. 서버 구조 · 애플리케이션 peak 기반으로 70~75% 상시, 80~85%는 경보설정, SSD, HDD 차이·백업구간 고려.
Q. 백업과 서비스 I/O 완전 분리 실전 방법은?
A. 백업용 프로세스(ionice -c2 -n7), 서비스는 고우선순위로, cgroup I/O 제한 + 반드시 cron 시간 분할.
A. 백업용 프로세스(ionice -c2 -n7), 서비스는 고우선순위로, cgroup I/O 제한 + 반드시 cron 시간 분할.
Q. 반복 장애 줄이려면?
A. 장애 이력 기록/공유, Alert Rule 지속 최신화, 인프라 이중화(RDS, S3 활용) 권장!
A. 장애 이력 기록/공유, Alert Rule 지속 최신화, 인프라 이중화(RDS, S3 활용) 권장!
실전 조언:
장애 메트릭, 로그, 복구 시나리오, 알람 룰을 꾸준히 문서화하여 피부로 익숙해지는 게 가장 현실적인 DevOps 성장법입니다.
장애 메트릭, 로그, 복구 시나리오, 알람 룰을 꾸준히 문서화하여 피부로 익숙해지는 게 가장 현실적인 DevOps 성장법입니다.